Today’s article is going to teach you how to turn your man pages into HTML. It’s a relatively straightforward process and handy if you want your man pages to be more easily read. It should be a quick article, as I have preexisting work to help along the way.
Again, making your man pages easier to read is really the only reason why I can think of for doing this – other than preparing them for uploading to share on a web site. I’m not entirely sure why you’d want to upload them, when there are already uploaded and maintained versions of man pages.
If you recall, the last article was about showing you how to find your man page’s location on disk. In that article, you learned about the whereis command. The reason that article was done first was so that I can save some time and just refer you to the first article.
So, yeah, click that last link and learn about the whereis command, saving me a bunch of time and typing! After all, I planned ahead! I swear, half these articles are so that I can refer to ’em later, I just forget that I wrote ’em. Wine might just be a factor.
Anyhow, with you having refreshed your memory by reading the previous article, let’s just jump right into it. Let’s learn how to…
Turn Your Man Pages Into HTML:
Like many other articles on this site, you’re gonna need an open terminal. If you don’t know how to open the terminal, you can do so with your keyboard – just press
Once you have a terminal open, you’ll want to install man2html. That should be in your default repositories, so I’ll save some time and just share how to install it in Debian/Ubuntu/derivatives. It’s just:
1 | sudo apt install man2html |
Once installed, we can check the man page and see that it defines itself as:
man2html – format a manual page in html
Which is, well, a pretty good description. That’s what it does. That’s what we’ll be using it for. Imagine that?!?
Now, the first step in the operation is finding the location of your man pages. To do that, we’ll use the whereis command – like so:
1 2 | $ whereis ls ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz |
The 3rd field is what we’re actually after, so you can use awk to help you out. That’d look more like this:
1 2 | $ whereis ls | awk ' {print $3} ' /usr/share/man/man1/ls.1.gz |
That’s the actual path to the man page for ls. You’ll need it for the next command. That’d look like:
1 | man2html /usr/share/man/man1/ls.1.gz > ~/Documents/man_ls.html |
Now, as you can see, the command first needs to know the path of the man page and then needs to know the path where you wish to save the output HTML file. You can adjust each according to your needs, using the > operand to determine where the resulting file is saved.
If you need a refresher on how to output the terminal to a file, click and read:
How To: Write Text To A File From The Terminal with “>” and “
(See, more foreshadowing!)
The output from your command should end up looking something like this:
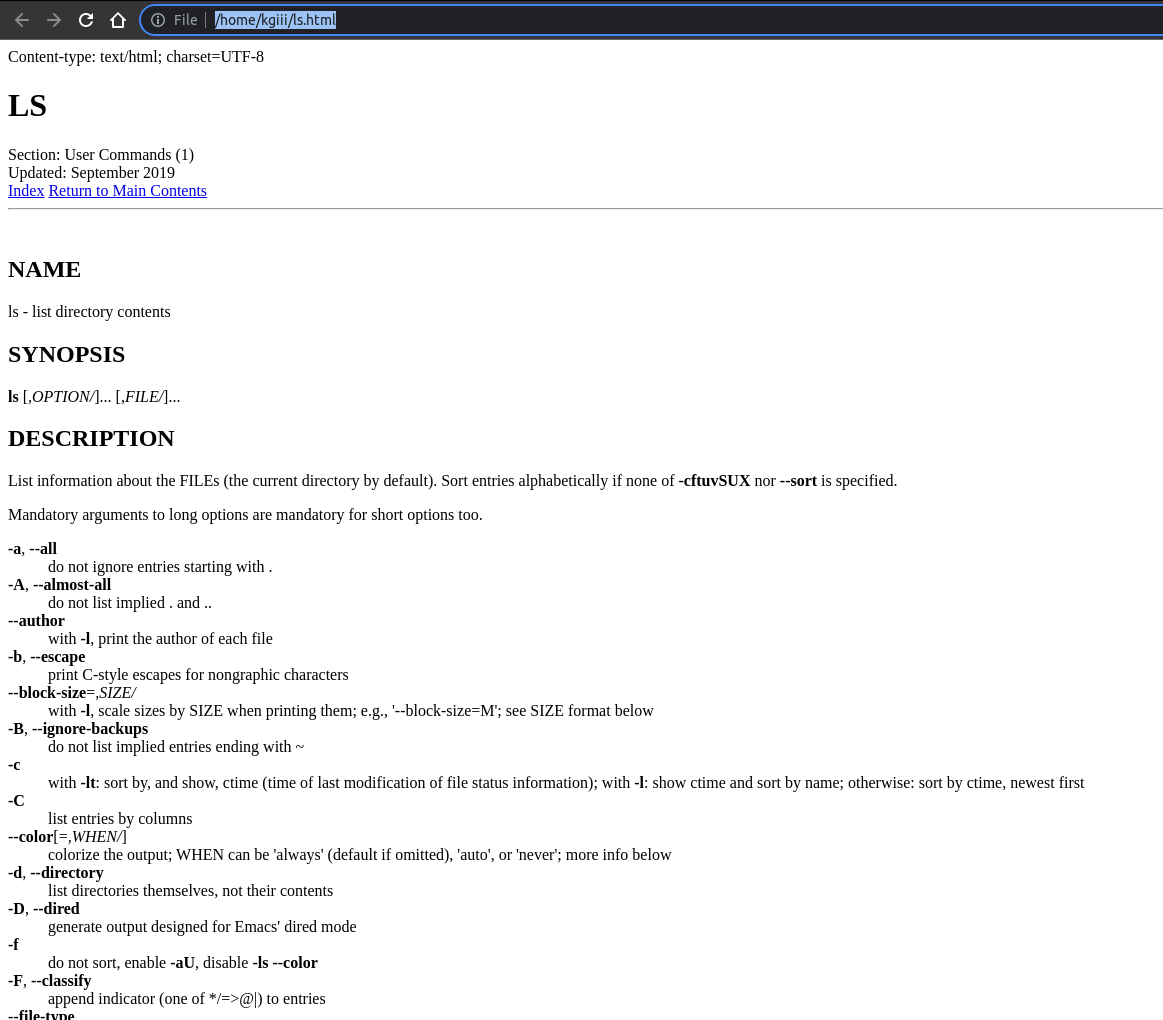
Anyhow, that’s actually all there is to it. Use the whereis to find the location of the man page. With that information you use man2html to write the HTML to a directory of your choosing. ‘Snot all that difficult, now is it? And to think, there are people afraid of the terminal!
Closure:
Well, there you have it. It’s a pretty simple article, mostly thanks to having written a lot of the information ahead of time – in other articles. Sometimes I plan on another article to follow an article, but I forget or it just gets lost in the shuffle. The good news is that the search function works well enough and I now have a whole lot of articles to reference! If nothing else, you now know how to turn your man pages into HTML – should you want to do so.
Until next time…
Thanks for reading! If you want to help, or if the site has helped you, you can donate, register to help, write an article, or buy inexpensive hosting to start your own site. If you scroll down, you can sign up for the newsletter, vote for the article, and comment.