This article was authored while I was sick and pukin’. Well, I’d mostly stopped puking while writing.. Thanks to a fantastic @GGG_246 from Reddit (No thanks to you folks on Linux.org who normally catch this stuff!) the entire intro was meant for Chromium and not Chrome.
This is because I was moving it from the old site to the new one, splitting it into two articles. The old article covered both Chrome and Chromium. Also, I was sicker than I’m gonna describe…
So, here you go… This is how to install Chrome browser on Ubuntu. (I am still not quite back to normal. Ask me about my bowels!)
Install Chrome Browser:
Let’s just jump right into it. You know what Chrome Browser is, or you wouldn’t be here. It’s also not very complicated. Let’s bust open your default terminal emulator by pressing CTRL + ALT + T and enter the following:
That’s it in the terminal. You’re done. When you finish the installation and start Chrome it will let you set it as the default in the terminal or GUI (if you want), among other things. Even better, the installation adds its own repository and will now automatically update the Chrome browser when the rest of the system is updated.
The repository contains the beta version as well, as well as the unstable version. With the repository added, you can install any of them easily. Be aware that beta may have bugs and that unstable is a nightly build that’s also prone to bugs. Using either means you understand the risks – and also kinda comes with the responsibility of reporting bugs.
Just use ‘apt install’ and they’re there for the taking. Install as you wish!
And, that’s about it really. There’s not a whole lot to this article and it’s intentionally short. I’ll do a very similar article about Chromium, so be prepared for that!
Closure:
One more article is in the books. This one is short for a couple of reasons. One of those reasons is that I’m not feeling well. That and power outages make me wonder if I’ll actually manage to do this for the full year. I should get a bunch of articles ahead! I’m eventually going to miss an article or two and I should probably prepare for that.
Thanks for reading! If you want to help, or if the site has helped you, you can donate, register to help, write an article, or buy inexpensive hosting to start your own site. If you scroll down, you can sign up for the newsletter, vote for the article, and comment.
Disk health is an important matter. Your storage media has a useful lifespan and the clock is ticking it from day one. Either hard disk drive (HDD) or solid state drive (SSD), your storage media has a limited lifespan.
You should plan on your drives failing because, given enough time or use, they will fail. This is a known limitation and there are ways to monitor disk health. Heck, in theory, many systems are supposed to monitor disk health and alert you of impending failure (see some BIOS options), though I’ve personally had poor luck relying on automated alerts. I periodically perform manual disk health checks.
We’ll be using “S.M.A.R.T.” (Self-Monitoring Analysis and Reporting Technology) and “smartmontools” for this exercise. It’s actually pretty accurate data – sorta… If it tells you there’s a problem, chances are good that drive health is an issue. However, drives are perfectly happy failing without giving you any warning at all. As I said in the opening paragraph, there’s a limit to how long your drives will last – but it will eventually and certainly fail.
At the same time, there are probably many of us who have ‘magical’ drives. I have an external HDD that gets used constantly – and it’s well over a decade old. On the other end of the spectrum, I’ve had drives fail within weeks of the warranty ending – and sometimes before the warranty ended. Drive failure is real and you should be prepared for it. The best way to be prepared for it is to have spares and a good backup plan.
So, let’s get started! (Also, click on the Wikipedia link above.)
Install ‘smartmontools’:
As I said above, we’ll be using ‘smartmontools’ to check the disk health with S.M.A.R.T. reporting. It’s a fairly robust application and is available for the major distros. Smartmontools is easily installed with your package manager, or you can do it in the terminal. If you want to do that, first open the terminal with CTRL + ALT + T and, once open, enter the appropriate command.
Debian/Ubuntu:
1
sudo apt install smartmontools
RHEL/Fedora:
1
sudo dnf install smartmontools
Arch/Manjaro:
1
sudo pacman -S smartmontools
Any of those will work on the appropriate systems. If you use a distro that’s not listed, it’s probably available in your repositories. It’s a fairly common tool and disk health is important!
This doesn’t work with NVMe drives. If you’re looking for NVMe support, look up ‘nvmi-cli’. I’ll probably write an article on the subject sometime in the future.
Anyhow, the tool you’ll be using from smartmontools is ‘smartctl’. It’s included with the package and is pretty easy to use. Read on to see how!
Check Disk Health With ‘smartctl’:
First, you should check to see if the device reports disk health by looking to see if the device has S.M.A.R.T. enabled. You can run this command:
1
sudo smartctl -i /drive/path
Where ‘/drive/path’, it’s often something like ‘/dev/sda’. You can look up your drive’s path easily enough. If it’s not enable, you can turn it on with:
1
sudo smartctl -s on /drive/path
Now, you can go ahead and check the status. To do that, you run:
1
sudo smartctl -a /drive/path
That should output some data. Remember how I highly recommended you click the Wikipedia link above? Well you should. The data in the report is fairly well-covered on the Wiki page. If you didn’t click it above, you can click now.
Anyways, the data in the report above might be old because the command may output some stale information. To refresh the data in the report, you can run a short (or long) test. In this first case, we’re going to run a short test (lasting 2 minutes or less) with this command:
1
sudo smartctl -t short /drive/path
Wait the couple of minutes as prompted and then run the original command again to get a report with the updated information:
1
sudo smartctl -a /drive/path
You can also run a long test. That’s done by changing the short to long, as in the command used above. It’s done like this:
1
sudo smartctl -t long /drive/path
That’ll take up to 10 minutes and you can check the results after that time has passed. Once again, you will simply run the same command you’ve been using all along:
1
sudo smartctl -a /drive/path
Anyhow, pay attention to the results in that report. They’ll give you a lot of information. You can check the results and technical details against the Wikipedia link. With that information in hand, you can keep a reasonable eye on your disk health.
There’s more to smartctl and even smartmontools, but not a whole lot that’s terribly interesting or important. Simply run man smartctl and look through the options. The most interesting/valuable disk health checks are covered above, but there’s nothing wrong with knowing more about your tools.
Closure:
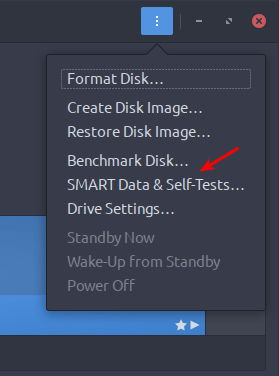
You know, if you install ‘gnome-disks’ then you can just do all of this graphically. Chances are good that all the distros out there that have smartmontools also have gnome-disks. If that’s more your style, just install it and poke around. It’s right there in the ‘three dot’ menu. Like so:
A nice GUI way! Give it a shot if you want!
But, that’d be cheating! It’d also be a much more basic article and where’s the fun in that? Nowhere. That’s where the fun isn’t. Seriously, the GUI method with gnome-tools works just fine for this if you’d prefer to go that route. Again, check your results against the Wikipedia link posted throughout the article.
Anyhow, there’s another article in the books. One more article said and done, in my attempt to keep this going for a full year. It has been pretty fun. This article is about disk health and reminds me that I need to write one about backing up your data. That’s good, ’cause it means I’ve still got all sorts of ideas for articles!
Thanks for reading! If you want to help, or if the site has helped you, you can donate, register to help, write an article, or buy inexpensive hosting to start your own site. If you scroll down, you can sign up for the newsletter, vote for the article, and comment.
balenaEtcher is a free software tool used to write .ISO files to USBs so that you can boot from them and install Linux. balenaEtcher is just one of many tools to do this, but it is both simple and effective. That makes it fit for purpose and is why it is getting its own article.
You’re going to need a blank USB drive, like a thumb drive. Well, it needn’t be blank but it should be. It needs to be large enough to meet the requirements of your distro – usually 4 GB is adequate. Larger is fine.
You’re also going to need the correct .ISO from the distro you’re trying to install. I have no way of knowing what that is, so here’s an article about picking the distro that’s right for you. You should verify the integrity of the .iso to eliminate it as a source of problems.
You’re also going to need to know how to boot to USB. That link will take you to an article that covers that, and includes DVD. It covers booting to something other than your default drive.
Finally, you’re going to need balenaEtcher. Head to this page and scroll down. If you scroll down, you’ll see many download options. It’s available for everything from Linux to MacOS.
Download the correct version for the operating system you’re currently using. If you download the AppImage, be sure to make it executable before trying to run it. Either way, you’ll need to download balenaEtcher (maybe install it) and then run it. That’ll vary depending on your OS, but they even have .deb and .rpm files available.
All set?
Let’s Use balenaEtcher:
With all those pieces in place, balenaEtcher is fairly self-explanatory. I’m going to assume you got it to work properly. If you can’t get it installed or running from the AppImage, just leave a comment and I’ll talk you through it for your system. You can also ask on Linux.org.
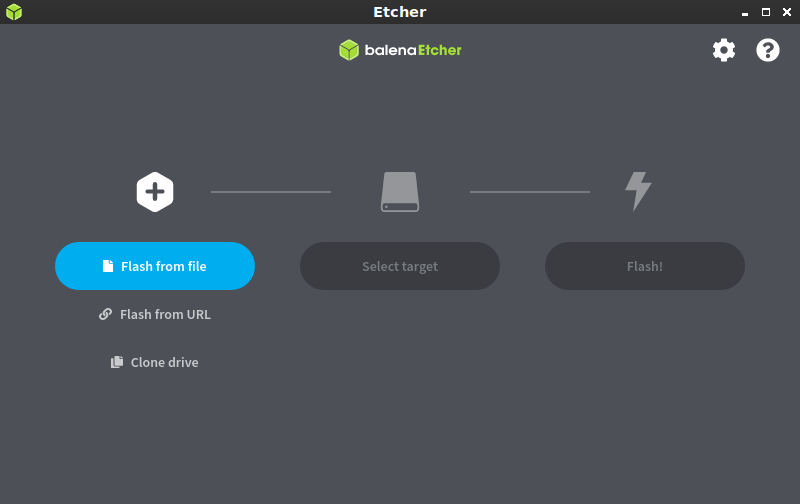
It’ll look something like this when you first open it.
In this case, you’ll pick “Flash from file”.
Then, you’ll click ‘Flash from file’ and doing so will let you navigate to and select the .iso you want to use. Do so, being sure to get it correct.
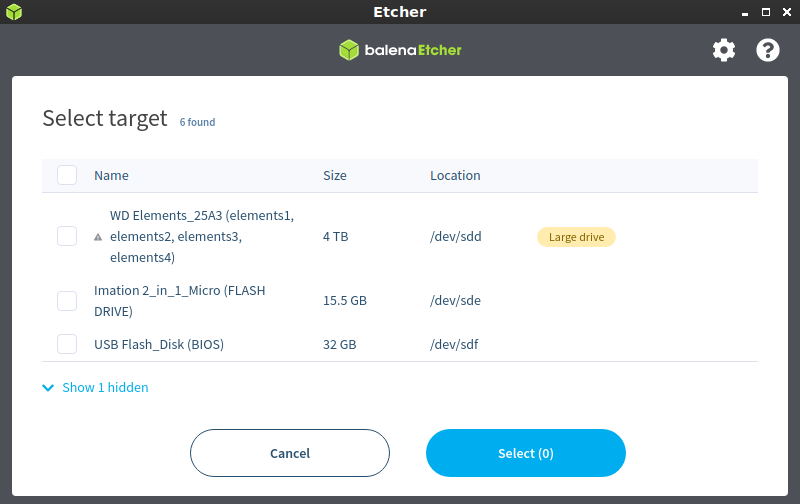
Next, you’ll select the target. The target in this case means the USB drive that you want to write the .iso to. So, that will be the smaller flash drive in most cases and will look something like this:
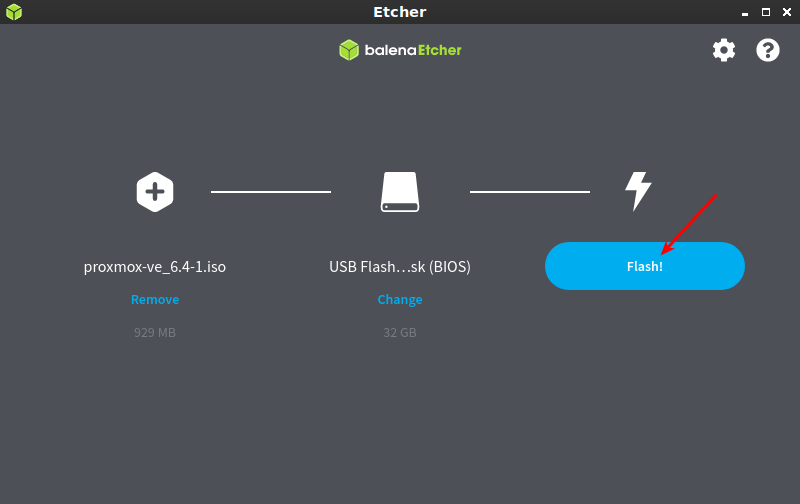
Select the right flash drive. Be very careful at this stage! This step can go horribly wrong!
There’s just one step remaining! You need to click the Flash button and wait for it to do its job writing the .ISO to the USB drive. It looks like this:
Click the ‘flash’ option and wait patiently while it does its job.
That could take a little while, though not all that long if you’re using USB 3.0. On USB 2.0 it takes a bit, so be prepared to wait – but not terribly long.
When this is all done, just close the program and your new USB device should be ready. You should be able to boot your computer, select the USB drive as the boot device, and then install Linux. Most of the time, it goes just swimmingly. If it doesn’t, ask for help.
Again, don’t forget to verify the integrity of the downloaded .ISO before you do any of this. The process for doing that varies, and the distro will tell you how on their download page. Have fun installing Linux!
I’ll probably eventually take the screenshots of me installing Linux in a virtual machine, but I haven’t done that article yet. It seems like a good future article to write.
Closure:
Well, there’s another article. This is just a nice, quick article. It’s handy for when you need to know how to use balenaEtcher, or when you need to tell someone else how to use it. It’s one of the articles I’d expect to see people linking to on a regular basis. “Hey, this is how you use Etcher!”
Thanks for reading! If you want to help, or if the site has helped you, you can donate, register to help, write an article, or buy inexpensive hosting to start your own site. If you scroll down, you can sign up for the newsletter, vote for the article, and comment.
Whenever I find myself unable to connect to a networked device, including websites online via the internet, one of the first tools I reach for is called ‘traceroute’. It’s not exclusive to Linux and you may know of the tool ‘tracert’ in Windows that does the same thing.
traceroute defines itself as this:
traceroute – print the route packets trace to network host
More realistically, it shows you the hops (devices) you go through in order to make a connection. See, when you connect to a different computer over the network, you don’t generally do so without going through other devices. Your data will travel through multiple devices to reach the source device and all those hops along the way are potential points of failure.
Sometimes those devices are under your control and you can actually do something about it. Other times, it’s just informative and all you can do is wait, or inform someone else and hope they fix it. If nothing else, you’ll know where your packets stopped or slowed down to the point of uselessness.
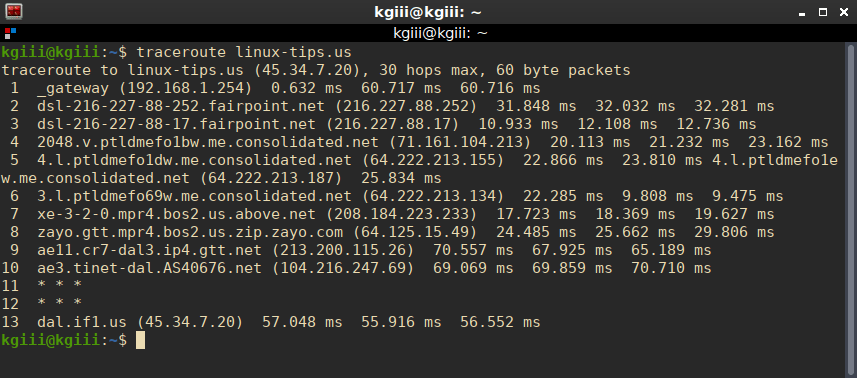
For example, there 13 hops (devices) between me and linux-tips.us.
See? There are 13 hops to reach my destination.
So, while that picture should explain it well enough, let’s get a little deeper.
Using traceroute:
You may find that traceroute isn’t already installed. If it isn’t, it’s absolutely in your default repositories. However you would normally install software is how you install this. If you look, traceroute is sure to be in there. So, go ahead and install it if it’s not already installed. For example:
1
sudo apt install traceroute
Just adjust that to your package management system and it’ll be in there. It’s that important a tool that I’m sure it’s in there. In fact, I’m a bit surprised that it’s not always installed by default, but it isn’t.
Now, the most basic usage is just like you saw in the image above.
1
traceroute linux-tips.us
So long as you’re within 30 hops and use 60 or fewer packets, that’s going to work well enough. The information it spits out is what devices it has traveled through (their hostname and IP address) and RTT – Round Trip Times. There are three of them because three packets are sent. Ideally, you’ll see your destination listed last. If not, you’ll see the closest you got to your destination.
If you see an asterisk, that means the device didn’t respond as expected. Frequently, this means the device is blocking ICMP. You can try to get around this by using ICMP ECHO (-I) or TCP (-T) packets. However, both of those will require elevated permissions, or the use of sudo.
1
2
3
sudo traceroute -I linux-tips.us
sudo traceroute -T linux-tips.us
All of this is mostly informative – unless you’re in control of the network and devices.
When it’s a network and devices under your control, you can use this information to troubleshoot. You can see the device names and time taken for packet transit, narrowing down your choices for troubleshooting.
When you’re using this over the public internet, you’re subject to other people who control the devices. If you find a break along the way, about all you can do is wait – or maybe use the data to contact your ISP (or hosting provider, if it’s your site that you’re trying to reach).
There are other options with traceroute. You can change the port you use, you can send more or fewer packets, you can not resolve hostnames, and more. To see the rest of the traceroute options:
1
man traceroute
That will fill you in with the many other choices you have. I find I don’t really need the advanced options, but system admins may need some of the features. As a regular user, I just use it to troubleshoot my own connections on my private network or when I am having web hosting/connectivity issues.
Closure:
And there you have it. Another article is in the books, and this time it’s just a nice easy article about the venerable traceroute. If you don’t already have this tool in your toolbox, it’d be worth adding and adding a basic familiarity to your mental toolbox.
Thanks for reading! If you want to help, or if the site has helped you, you can donate, register to help, write an article, or buy inexpensive hosting to start your own site. If you scroll down, you can sign up for the newsletter, vote for the article, and comment.
This article is going to be a limited look at cURL, a Linux application used in the terminal to transfer data. cURL is a very extensive program and we’ll just be scratching the surface. You’ll see why we’re just scratching the surface soon enough. It’s a very comprehensive application.
So, what is cURL? It’s an application that you use in your terminal to transfer data. However, as said, it’s an insanely complicated program. We’re just barely going to scratch the surface. Let’s start with the definition.
First, ‘man curl’ defines itself nice and easily:
curl – transfer a URL
However, if you keep reading to find the description, you’ll find this gem:
curl is a tool to transfer data from or to a server, using one of the supported protocols (DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, TELNET and TFTP). The command is designed to work without user interaction.
curl offers a busload of useful tricks like proxy support, user authentication, FTP upload, HTTP post, SSL connections, cookies, file transfer resume, Metalink, and more. As you will see below, the number of features will make your head spin!
Yeah…
In fact, while we’re here, why don’t you have a look at the man page for cURL. Really, click that link! I think that may be one of the longest man pages out there. cURL was originally released in 1997 and appears to have picked up everything along the way.
We’ll just be going over installing it and a couple of ways you can get started using it. To learn more, read the man page!
Using cURL:
There’s some chance that it didn’t come installed with your distro’s basic installation, so let’s first cover some ways of installing it. It’s sure to be in your default repositories for any major distro, and will almost certainly be trivial to install.
Open your terminal by pressing CTRL + ALT + T and use the correct following command to install it:
Debian/Ubuntu/Derivatives:
1
sudo apt install curl
OpenSUSE/Derivatives:
1
sudo zypper install curl
RHEL/Fedora/Derivatives:
1
sudo yum install curl
Arch/Derivatives:
1
sudo pacman -Sy curl
If your distro isn’t listed above, read the documentation for your distro’s package manager. If it’s not available, you can always build it from source. The project’s homepage can be found here.
With cURL now installed, and your terminal still open, you can test it easily enough. First, try this command:
1
curl https://linux-tips.us/temp/sample.txt
That should give you a nice message. It’ll appear in your terminal and that’s it. When you close the terminal window, the message will be gone. So, what if you want to download it? For that, you use the -O switch. Let’s try something:
1
2
3
4
cd Downloads
mkdir temp
cd temp
curl -O https://linux-tips.us/temp/sample.txt
That will make ‘sample.txt’ download to that directory. It’s not entirely unlike wget in those regards. If you want to change the name of the fetched file, you use the -o switch and the new name. So, the above code would look like this:
That will save sample.txt as example.txt and both of those commands will show you the transfer’s progress. This specific file isn’t large enough for that to really matter, but it’s noteworthy that it does so for future transfers.
Those are just a couple of ways to use cURL, and that’s it. It’s seriously powerful and flexible. You can read the man page and learn more about it, as it is a tool we should all have in our toolboxes. It’s useful in many situations and is worth spending some time to learn more about it.
Closure:
There’s another article in the books! As mentioned, it’s just a very limited look at cURL. To do a full tutorial would take days and days worth of articles and I’m much happier just exposing new users to the basic functionality. Even if you already have it installed and know how to use it, be sure to curl the sample.txt!
Thanks for reading! If you want to help, or if the site has helped you, you can donate, register to help, write an article, or buy inexpensive hosting to start your own site. If you scroll down, you can sign up for the newsletter, vote for the article, and comment.